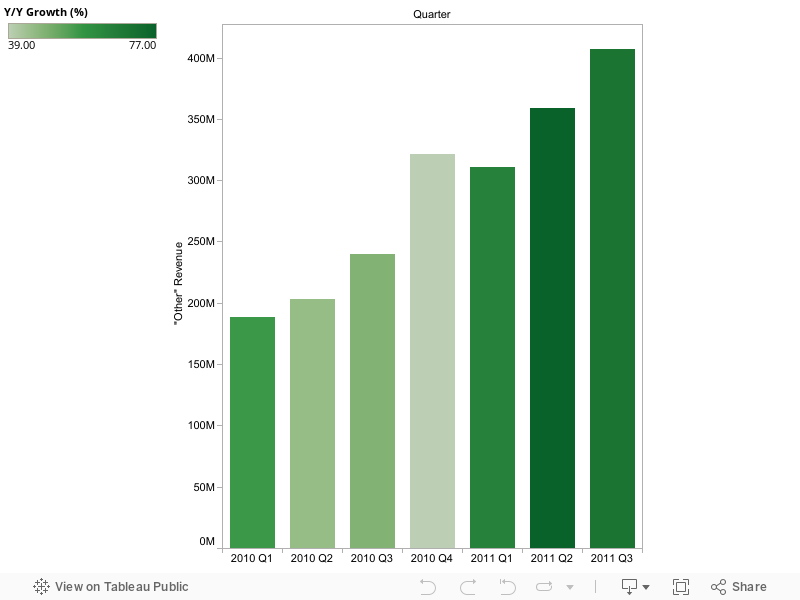
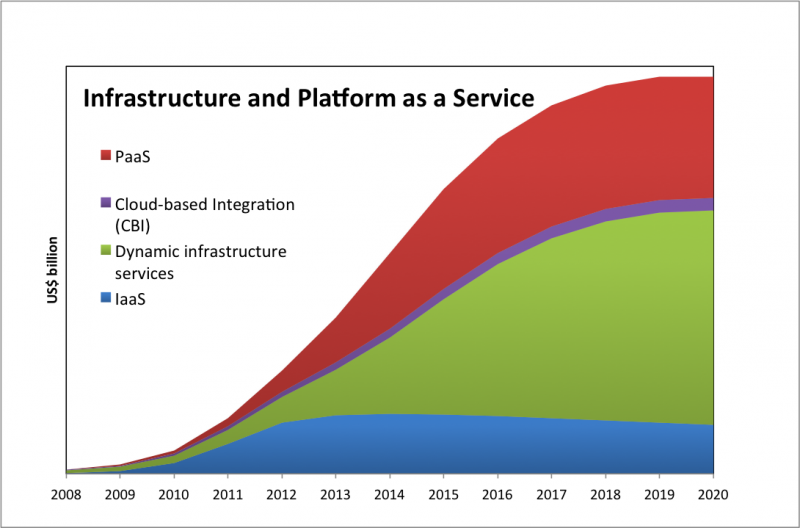
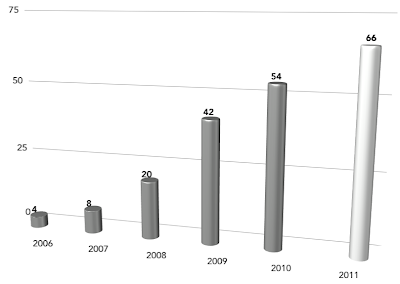
The recent Amazon outage has created some heated discussion as to whether Amazon’s services are enterprise ready or not. Much of the discussion seems to miss the point. For example, saying that Amazon is not enterprise-class is like saying an IBM x-server is not enterprise-class. Not very helpful and not very meaningful.
Amazon is a provider of compute and storage, like the aforementioned server. Give that server RAID direct-attached-storage, or dual-homing to a SAN, power from two UPSs and a mirror image of itself in another data center and you can perform synchronization between the two. Lo and behold, enterprise-class computing!
This can all be achieved with Amazon using different ‘Availability Zones’ in more than one Region and the appropriate software. And of course there is an associated price.
The reality is that the majority of Amazon’s clients are startups (many in the social networking space) that are willing to take the risk (or don’t comprehend it) in return for scalability, agility and above all the right price. Another significant group of clients are enterprises in search of cheap, agile compute for problems requiring mass horizontal scalability, but not persistence.
The really fascinating question behind this outage is the economic one, i.e. what level of risk/cost ratio are companies willing to tolerate for Information Technology.
Countless small enterprises that make heavy use of IT don’t have diesel backup and rely on their electrical utility to provide adequate uptime… sans SLA I might add. This is exactly the calculation that anyone using Amazon and its ilk is making–whether they are aware of it or not.
The cloud is all about economics—as are public electrical utilities—and we are in an important phase in the ongoing maturation of Information Technology: a field who’s economics have long been cloudy (pun intended) to say the least.